1、安装浏览器驱动
firefox
https://link.zhihu.com/?target=https%3A//github.com/mozilla/geckodriver/releases/
chrome
https://link.zhihu.com/?target=https%3A//sites.google.com/a/chromium.org/chromedriver/
IE
https://link.zhihu.com/?target=http%3A//selenium-release.storage.googleapis.com/index.html
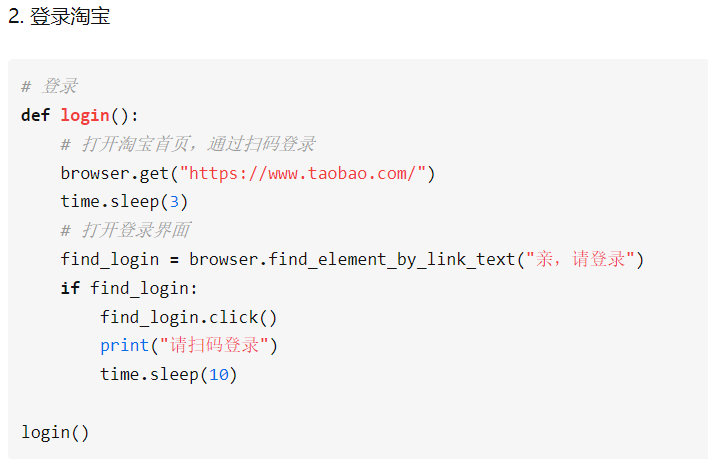
selenium操作浏览器
第一步:
导入webdriver模块
from selenium import webdriver打开浏览器
browser = webdriver.Chrome()打开指定网址
browser.get("https://www.taobao.com/")针对浏览器的主要操作方法:
创建浏览器对象:driver = http://webdriver.xxx()
窗口最大化:maximize_window()
获取浏览器尺寸:get_window_size()
设置浏览器尺寸:set_window_size()
获取浏览器位置:get_window_position()
设置浏览器位置:set_window_position(x,y)
关闭当前标签/窗口:close()
关闭所有标签/窗口:quit()
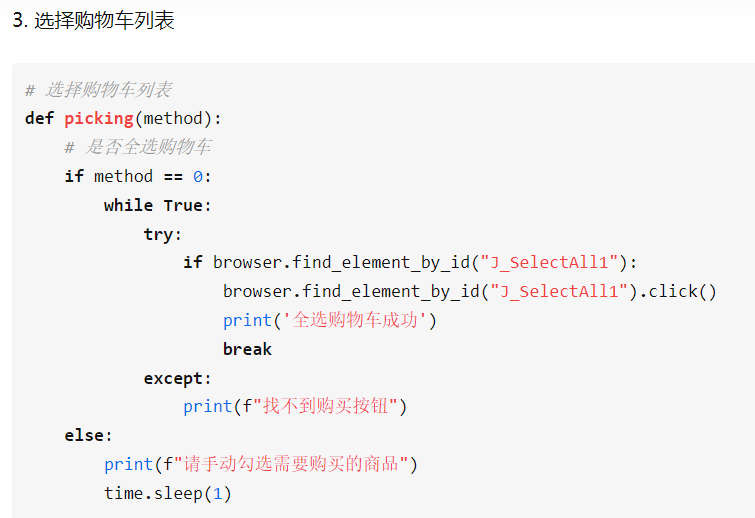
selenium定位元素
模仿真实点击浏览器的行为,先定位网页元素,才能进行各种操作
id定位:driver.find_element_by_id(value)
name属性值定位:driver.find_element_by_name(value)
类名定位: driver.find_element_by_class_name(value)
标签名定位: driver.find_element_by_tag_name(value)
链接文本定位:driver.find_element_by_link_text(value)
部分链接文本:driver.find_element_by_partial_link_text(value)
xpath路径表达式:driver.find_element_by_xpath(value)
css选择器:driver.find_element_by_css_selector(value)
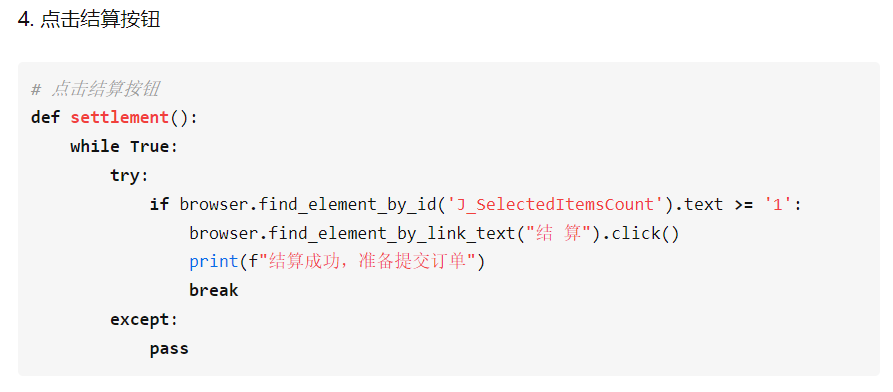
selenium操作网页
定位到元素后,需要对网页进行各种操作,比如点击,刷新,保存等操作
点击展开新的页面,点击方法:element.click()
其它几个方法操作:
请求某个url:drive.get(url)
刷新页面操作:refresh()
退回到之前的页面:back()
前进道之后的页面:forward()
获取当前访问页面url:current_url
获取当前浏览器标题:title
保存图片:get_screenshot_as_png()/get_screenshot_as_file(文件)
网页源码:page_source
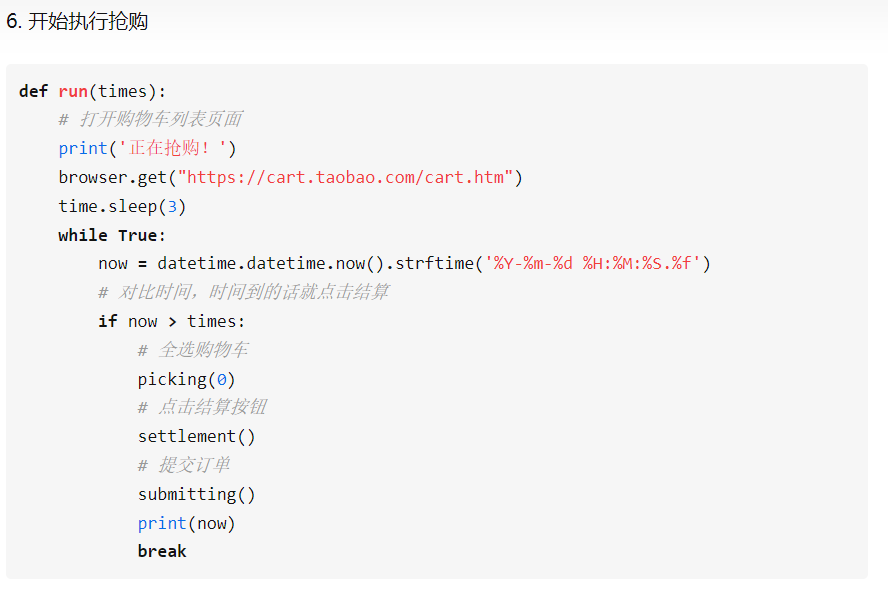
参考案例